scrapy 框架初使用及爬取 LOL 信息
零、真前言
这篇文章是由 2018 年 4 月 16 日首次发布于 csdn,后来由于 “逃离csdn” 的想法中,将之前发布的文章重新排版,发表在个站中。
一、前言
了解到爬虫技术大概有 18 个月了,这期间自己写过几个爬虫,也 fork 过几个流行的爬虫 repo,包括 bilibili-user、iquery、WechatSogou 等,但一直没系统的写过爬虫,上一次心血来潮(17 年 10 月),想要爬下关于英雄联盟的数据,主要想获得皮肤原画数据。
当时决定的目标网站是英雄联盟中文官网,数据准确且更新快。LOL 数据库,但苦于该网页全篇使用 js 载入数据,无法直接读取,就退而求其次,改变目标网址多玩-英雄联盟-英雄数据库。
技术使用混杂,主要利用 requests+bs4 完成爬取,部分内容使用 scrapy 抓取,逻辑结构混乱,代码可见 spider-on-lol/v1.0/,功能基本实现,但不够美。七天之前,看到了这些代码,决定用 scrapy 重新实现功能,完成整个逻辑设计,这中间遇到了很多问题,从中得到了学习,完整代码可见 spider-on-lol。
二、爬虫设计全思路
- 目标网站:LOL 数据库
- 爬取内容:
- 英雄姓名
- 英雄头像
- 物品名称、id
- 物品图片
- 英雄皮肤原画
- 英雄背景故事
- 技术:scrapy,splash,docker
- 难点
- 图片获取
- js 页面数据的获取
- 中文编码
三、环境搭建
工欲善其事,必先利其器。
- 1、 开发语言:python v3.6.5
- 2、开发语言环境:anaconda v1.6.9 (非必须,但隔离环境是一个好习惯)
- 3、docker 安装
- 4、splash
- 5、一些第三方库:
- scrapy:
conda install Scrapy - scrapy_splash:
conda install scrapy_splash
- scrapy:
四、什么是 Scrapy?什么是 Splash?
1、Scrapy
Scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
简单的说,使用 scrapy 爬虫,只需要简单的代码可以完成复杂的爬虫工作。
其运行流程如下图所示:
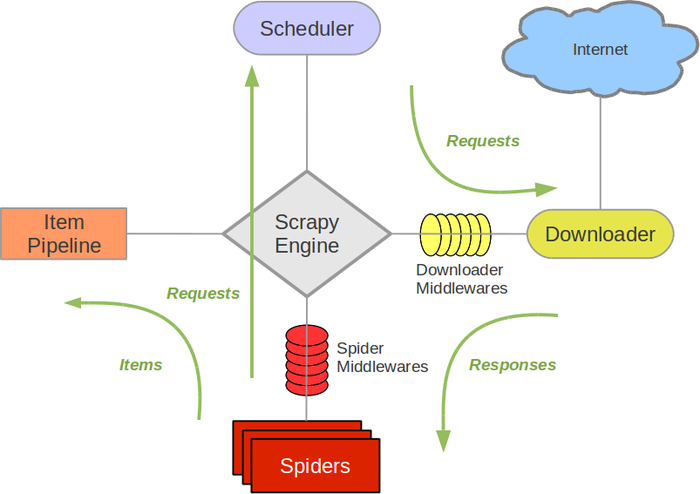
通过这张图可以了解 scrapy 的执行过程,而理解这个过程对后面的编写以及排错有重要作用。 推荐几个几个关于 scrapy 的网站:
- Scrapy1.0中文文档(重要)
- Scrapy1.5官方文档
- Scrapy0.2.2中文文档
- Scrapy实战(重要)
- scrapy 的教程要对应版本,新版本加了不少特性,新手容易在版本特性上出错
2、Splash
splash 是一个 JavaScript 渲染服务,它可以渲染带有 js 的网页,并返还一个完整的页面。 它的优势在于:
- splash 作为 js 渲染服务,是基于 Twisted 和 QT 开发的轻量浏览器引擎,并且提供直接的 http api。快速、轻量的特点使其容易进行分布式开发。
- splash 和 scrapy 融合,两种互相兼容彼此的特点,抓取效率较好。
splash 基于 docker 技术,有多种功能,在本文中只用到了最基础的渲染 js 功能。
更多关于 splash 的资料,请参照:Splash官方文档
五、第一类爬虫
第一类爬虫,也是第一个爬虫,目的是爬取英雄名字及称号,看上去好像没那么复杂。
1、定义 item
打开 items,添加如下代码:
import scrapy
class LOLHeroNameSpiderItem(scrapy.Item):
'''继承自scrapy.Item,在spiders/lol-hero-name-spidder.py中使用'''
# name英雄名称,e_name英雄英文名称(即英雄id),title英雄称号
hero_name = scrapy.Field()
hero_e_name = scrapy.Field()
hero_title = scrapy.Field()
定义三个字段,作为后续获得的数据的容器,以便于进入 pipeline 操作。
2、编写 pipeline
pipelines 是对 spider 爬取到的 item 进行处理的过程,在这个爬虫中,我们需要对获得的数据进行转码并储存在 json 文件中。记得将 LOLHeroNamePipeline 添加到配置文件 settings.py 中。
import codecs
import json
class LOLHeroNamePipeline(object):
def __init__(self):
# codecs,python编解码器,以字节写方式打开一个文件,方便后面的转换中文
# 关于codecs可以查看https://docs.python.org/3/library/codecs.html
self.file = codecs.open('lol-hero-name.json', 'wb', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item)) + '\n' # line是str类型
# 向codecs("wb")打开的文件写入line经过utf-8编码后再经过unicode编码,最后存储的字符是中文
self.file.write(line.encode('utf-8').decode('unicode_escape'))
return item
3、编写 spider
from scrapy.http import Request
from scrapy.spiders import Spider
from scrapy.selector import Selector
from scrapy_splash import SplashRequest # 引入splash组件,获取js数据
from lolSpider.items import LOLHeroNameSpiderItem
class LOLHeroNameSpider(Spider):
'''
第一个爬虫类,爬取英雄联盟所有英雄名字及称号
'''
name = "LOL-Hero-Name" # 唯一的名字,命令行执行的时候使用
# 同一个项目下,多个spider对应不同的pipeline,需要在spider中修改配置,setting.py中不做pipeline配置
custom_settings = {
'ITEM_PIPELINES':{
'lolSpider.pipelines.LOLHeroNamePipeline': 300,
},
}
allowed_domains = ["http://lol.qq.com/web201310/info-heros.shtml"] # 允许爬取的网站域
start_urls = ["http://lol.qq.com/web201310/info-heros.shtml",] # 开始爬取的第一条url
def start_requests(self):
for url in self.start_urls:
# 处理start_urls,以splashRequest的方法执行parse方法
yield SplashRequest(url=url, callback=self.parse, args={'wait': 0.5},endpoint='render.html',)
# parse方法用于处理数据,传入一个response对象
def parse(self, response):
# sites是一个可迭代对象,它代表了从response对象中获取某些数据而形成的可迭代对象
# 使用xpath方法找到特定的元素组成的数据,在这里代表“找到一个id为jSearchHeroDiv的元素它的所有li元素,很多个li元素,所以成为一个可迭代对象
# XPath是一门在XML、HTML文档中查找信息的语言,它可以查找元素。教程可见http://www.w3school.com.cn/xpath/index.asp
# 之前的xpath很长,但不需要对着网页源代码查找,请见http://www.locoy.com/Public/guide/V9/HTML/XPath%E6%8F%90%E5%8F%96.html
sites = response.xpath("//*[@id=\"jSearchHeroDiv\"]/li")
items = []
# 对sites的每一个li元素进行循环
for site in sites:
item = LOLHeroNameSpiderItem()
item['hero_name'] = site.xpath("a/@title").extract_first().split(" ")[1]
item['hero_title'] = site.xpath("a/@title").extract_first().split(" ")[0]
item['hero_e_name'] = site.xpath("a/@href").extract_first()[21:]
yield {'name':item['hero_name'],'title':item['hero_title'],"e_name":item['hero_e_name']}
items.append(item)
# return 也可以完成yield的任务(在这个文件内),两者都可以输出到json文件(保留一个就好hh)
return items
4、解析爬取过程
- 一个 spider 文件中定义一个爬虫类,继承自 scrapy.spiders,必须拥有类属性 name 和 start_urls,前者是命令行启动爬虫的关键,后者是 scrapy 调度器开始的条件。
- 注意这里有个 custom_settings,这个属性代表着爬虫自带的设置条件,在执行爬虫时,这里的属性值覆盖掉 scrapy 工程的默认设置,在多个爬虫共处一个工程的环境下,custom_settings 非常重要。
- 在 start_requests() 方法中,返回一个 SplashRequest() 方法,方法传递参数 url,parse()。
- 之后在 parse() 方法中,进行数据的提取,一般是通过选择器先获得一个可迭代对象,而选择器常用的有 css,xpath 两种,个人偏向于xpath,关于xpath的学习请见xpath学习。获得一个可迭代对象后,用 for 进行迭代,迭代过程中进行操作,此时就可以创建 item 对象,并作为容器装入取得的数据,再经过 pipeline 的操作,在这个爬虫中,最终的输出是一个特定格式的 json 文件。
- 同样工作流程的,还有 LOLItemNameSpider,LOLHeroSkinSpider。
- 记得启动splash服务。
- 这部分爬虫没什么坑,理解了scrapy的原理就很明了了。
六、第二类爬虫
在这里,我们准备爬取图片,scrapy 对图片的支持相当完善,在最新的版本(1.5)中,已经支持:
- 避免重新下载最近已经下载过的数据
- 将所有下载的图片转换成通用的格式(JPG)和模式(RGB)
- 缩略图生成
- 检测图像的宽/高,确保它们满足最小限制
这里我们以爬取并下载 LOL 英雄皮肤原画为例,简要说下,如何利用 pipeline 自动下载。
1、定义 item
class LOLHeroSkinSpiderItem(scrapy.Item):
# image_urls图片链接,image_names图片名称,image_id图片保存名称
image_urls = scrapy.Field()
image_names = scrapy.Field()
image_id = scrapy.Field()
item 的定义和第一类爬虫类似,其实这是因为 python 弱类型,作为容器,不分类型,具体涉及到的类型操作由人工完成。
2、编写 pipeline
import json
import codecs
from scrapy import log
from scrapy import Request
from scrapy.http import Request
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
class LOLHeroSkinInfoPipeline(object):
'''
pipelines是对spider爬取到的item进行处理的过程
关于scrapy的核心架构可参见https://blog.csdn.net/u012150179/article/details/34441655
'''
def __init__(self):
# codecs,python编解码器,以字节写方式打开一个文件,方便后面的转换中文
# 关于codecs可以查看https://docs.python.org/3/library/codecs.html
self.file = codecs.open('lol-skin-info.json', 'wb', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item)) + '\n' # line是str类型
# 向codecs("wb")打开的文件写入line经过utf-8编码后再经过unicode编码,最后存储的字符是中文
self.file.write(line.encode('utf-8').decode('unicode_escape'))
return item
# 对应LOL-Hero-Skin
class LOLHeroSkinPipeline(ImagesPipeline):
# file_path()方法将保存的图片文件重命名,返回str
def file_path(self, request, response=None, info=None):
image_guid = request.url.split('/')[-1]
return 'full/%s' % (image_guid)
# 参加https://www.jianshu.com/p/c12d2ac7d55f
def get_media_requests(self, item, info):
for image_url in item['image_urls']:
yield Request(image_url)
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
return item
这里的 pipeline 就比第一类爬虫复杂点。
- LOLHeroSkinInfoPipeline 类,没什么好说的,依旧保存下载文件的信息并输出到 json。
- LOLHeroSkinPipeline 类,这个类继承自 ImagesPipeline,可以通过重写这个父类的几个方法,简单的实现图片下载的任务。
- scrapy 保存图片是,默认以图片的 sha1 hash 值进行保存,通过 file_path() 方法可以制定待保存图片的名字,详情可见 ImagesPipeline 下载图片。
- 记得将新创建的两个类,添加到配置文件 settings.py 中,同时对于图片爬取,要在配置文件中设置属性 IMAGES_STORE 制定图片保存位置。
3、编写 spider
# -*- coding:utf-8 -*-
import sys
import scrapy
from scrapy import Request
from scrapy.spiders import Spider
from scrapy_splash import SplashRequest
from lolSpider.items import LOLHeroSkinSpiderItem
class LOLHeroSkinSpider(scrapy.Spider):
'''第五个爬虫类,爬取所有英雄皮肤'''
name = 'LOL-Hero-Skin'
custom_settings = {
'ITEM_PIPELINES':{
'lolSpider.pipelines.LOLHeroSkinPipeline': 300,
'lolSpider.pipelines.LOLHeroSkinInfoPipeline':301,
},
'IMAGES_STORE':'../lolSpider/lolSpider/img/hero_skin_img',
}
# 从英雄列表中获取英文名,构造start_urls
start_urls = []
base_url = "http://lol.qq.com/web201310/info-defail.shtml?id="
with open('./lol-hero-name.json','r') as f:
for line in f.readlines():
i = line.find("e_name") +10
suf_url = line[i:-3]
start_urls.append(base_url+suf_url)
# http header
default_headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch, br',
'Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Host': 'http://lol.qq.com/web201310/info-defail.shtml?id=Aatrox',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36',
}
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(url=url, callback=self.parse, args={'wait': 0.5},
endpoint='render.html'
)
def parse(self,response):
text = response.xpath("//*[@id=\"skinNAV\"]/li")
for i in text:
item = LOLHeroSkinSpiderItem()
# 获得图片id,为了进一步的重命名
item["image_id"] = i.xpath("a/img/@src").extract_first().split("/")[-1].replace("small","big")
# 动态页面,无法抓取到bigxxx.jpg,但可以通过replace构造完整url
image_urls = i.xpath("a/img/@src").extract_first()
image_urls = image_urls.replace("small","big")
temp = []
temp.append(image_urls)
item["image_urls"] = temp
# 皮肤的中文名称,若为“默认”,则添加英雄名称
image_names = i.xpath("a/@title").extract_first()
if image_names == "默认皮肤":
item['image_names'] = image_names + " " + response.xpath("//*[@id=\"DATAnametitle\"]/text()").extract_first().split(' ')[-1]
else:
item['image_names'] = image_names
yield item
4、解析爬取过程
- 一样的创建一个爬虫类,继承自 scrapy.spiders,设置 name 属性。
- 注意这里的 custom_settings 多了一个 IMAGES_STORE 定义储存位置。
- 由于要渲染多次 js 画面,可以有两种方法。
- 第一种方法:利用 splash 函数,手动翻页。
- 第二种方法:将所有页面放入 start_urls 中,逐个的渲染,这里选择第二种方法。
- 读取第一个爬虫获得的 lol-hero-name.json 数据,构造 140 个url,添加到 start_urls 中。
- 在 parse() 方法中,遇到了一个大问题,查找了很多资料最终才得以解决。
- 错误提示
Missing scheme in request url: h,这是因为 scrapy1.0 中,extract_first() 返回的是byte,而 scrapy pipeline 准备下载需要的是列表,并且取列表第一个元素。例如:a = “http://demo.lightl.fun” ,b = [“http://demo.lightl.fun“] 。若是前者a[0]则为’h’,若为后者b[0]则是完整的网址。 - 简单的解决方法,若直接从 xpath 或 css 选择器中获取数据,而不用进行二次处理,直接将 extract_first() 替换为 extract() 返回列表。
- 复杂的解决方法,若从选择器中获取数据后进行二次处理,可以新建一个列表,使其 append 处理后的数据再交给 item,也是返回列表。
- 错误提示
七、关于设置 settings.py
如果整个爬虫只有一个 spider 文件,那么可以直接在 settings.py 中修改配置,否则,使用 custom_settings 进行设置。
常见的设置项如下:
- splash相关设置
SPLASH_URL = 'http://172.17.0.2:8050/' # splash在docker下的url,由机器而异,查找ip可参见https://mozillazg.com/2016/01/docker-get-containers-ip-address.html
# 下载中间件
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
# 爬虫中间件
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter' # 去重过滤器(必须)
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage' # 使用http缓存
- 是否遵守ROBOT协议,默认是遵守
ROBOTSTXT_OBEY = True
- 下载延迟,防止被禁ip
DOWNLOAD_DELAY = 1
- 机器做了代理,可以这么设置让scrapy不走代理
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
}
- 禁止cookies
COOKIES_ENABLED = False
八、scrapy防ban策略
主要参考如何防止被ban之策略大集合
- 设置 download_delay
- 禁止 cookies
- 设置 header,必要的话可以多个 header 随机使用
- 使用 ip 池
- 分布式爬取
九、反思
- 1、代码是人写的,工具是人写的,现有的框架无法满足所有人,而能够修改框架满足需求很重要。
- 2、多用 google、stackoverflow。
- 3、静下心,不能急于求成,如果一开始就认真的理解 scrapy 工作流程,事会少一半。
- 4、以官方英文文档为主,中文文档以辅,也不是说中文化不好,只是有时候更新慢,有些概念混乱。
- 5、如何有效的调试程序,还有待学习。